Project Directories
I find it beneficial to use a specific file directory for each statistical analysis or data visualization project, regardless of the statistical program. This simplifies revisiting the project, as all needed documents, data and code files are in the same directory. Furthermore, working in projects in R simplifies code for importing data, and sharing projects.
To make a new project, click “File” and “new project”. Choose “New Directory” and “New Project”, save the directory to your preferred location. Any file you save in this directory will be displayed under “Files”.
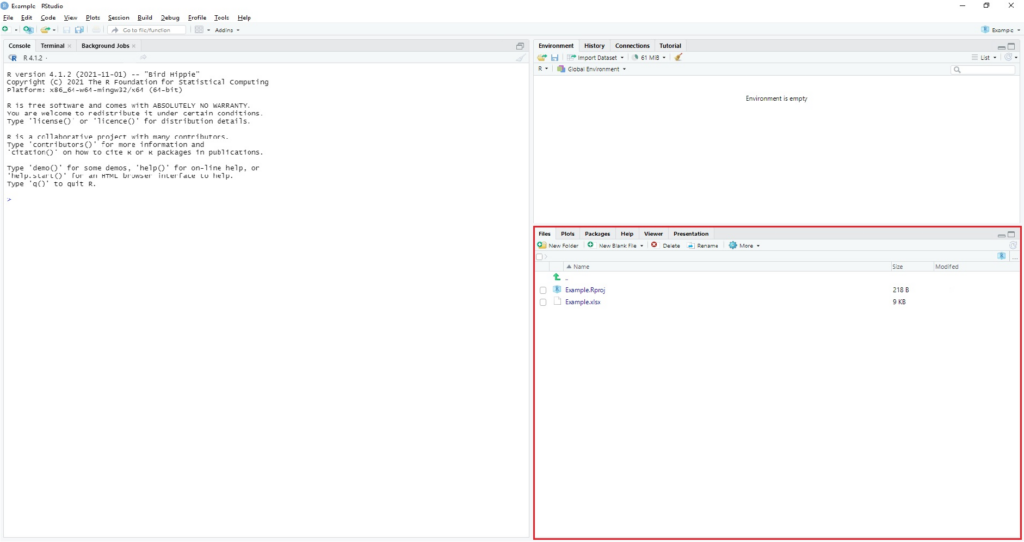
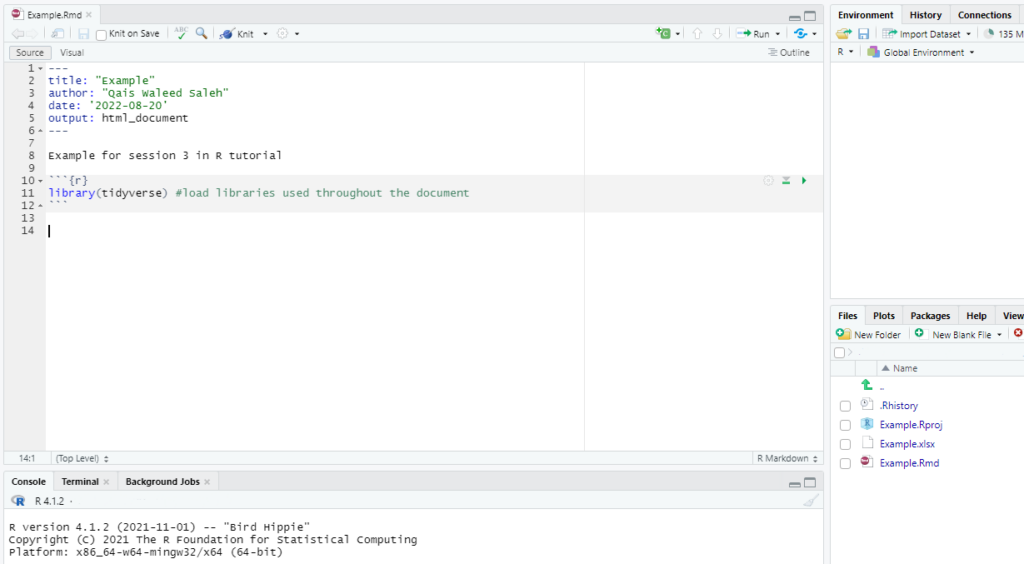
Writing Code
Open a file in which you can write your code, this can be Rscript, Rmarkdown or the new Quatro. I prefer to use Rmarkdown. Here, I usually write a few words about the project, then write the code in chunks.
In the first code chunk I usually write code that loads all the libraries that I intend to use in the project.
Importing Data
Now we are ready to import data. From the previous picture you can see an xlsx file under files, I moved this file to the R project directory manually. To import it click “Import Dataset” under the environment tab, then choose the type of file.
A new window is opened. By clicking browse, we are shown the R project directory, where the xlsx file is. Opening this file displays the data under “Data Preview”. Under each column R shows what type of data it thinks is represented. We can change the type of data by clicking the column heading, we also have the option to include or skip the column.
The dataset is imported as a named object. A simple object name will simplify subsequent code. We can change the name of the dataset object under “Import Options” – I chose to name this dataset “a”.
“NA” means not avaliable and refers to missing values. Write how missing data has been coded in the dataset here. If missing values are blank, leave the tab blank.
The code that R generates in this window is displayed under “Code Preview”, I usually copy this code and paste it to a separate code chunk in my Rmarkdown file. This simplifies revisiting the project as I can run the code instead of clicking through the import dataset option again.
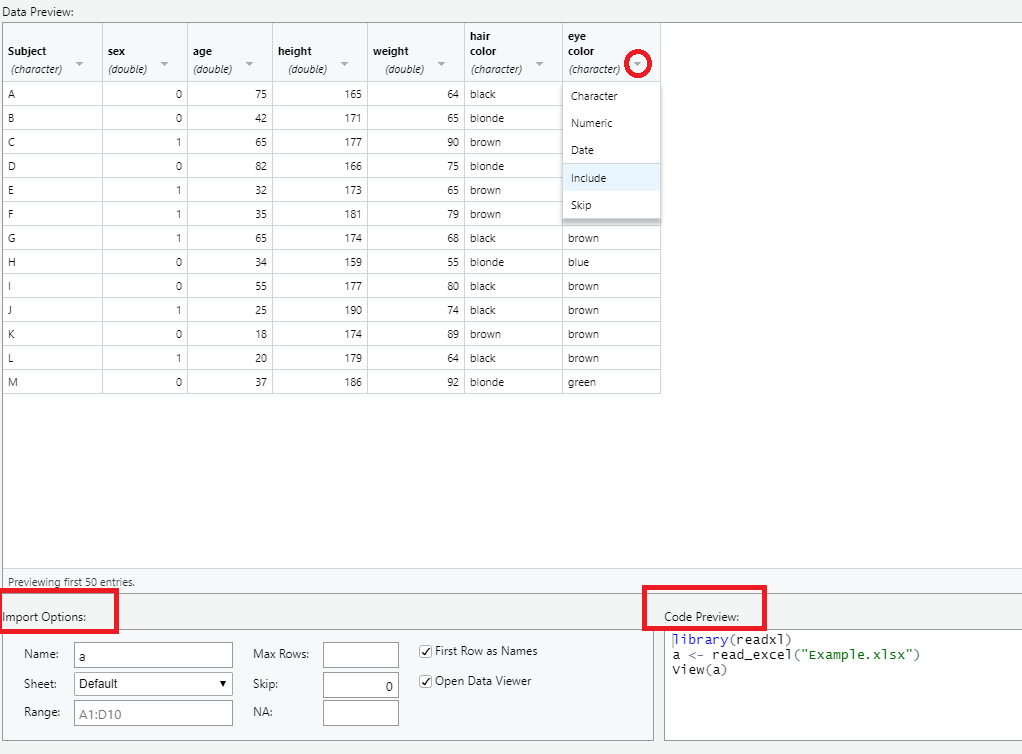
Types of data
As can be seen above, there are three main types of data in R – character, numeric and date.
However, character and numeric data are subcategorized in R.
According to “R for Health Data Science“:
- Numeric variables or continuous variables can be designated as “numeric”, “num”, “integer” or “double”. “Integer” are numerical values without decimals while “double” are numerical values that contain decimals. The designation of numerical variables is rarely an issue.
- Categorical variables can be:
- Character: letters, words, sentences – no hierarchy or order
- Factor: categorical variables with an order
- logical: True or false values
Explore the Imported Dataset
The following commands are helpful:
- view() – opens a window displaying an object, for example your imported dataset
- str() – if for a dataset, it shows a short summary of the dataset, most importantly data type for each variable
- class() – if for a variable, it shows its data type (hint: if your dataset is named “a” and in it is a variable named “age”, and you want to tell R to choose this variable, write “a$age”).
- levels() – if for a variable, it shows if there are and what type of levels or hierarchy values have within a variable. If the variable has no levels the command will return the answer “NULL”.
I rarely find it necessary to change a numeric variable’s data type. Factor variables are however imported as numerical variables if the values are coded in numbers, or as character variables with no levels or hierarchy if the values are text.
In the image below, the str() function shows a quick overview of a dataset, notice that the variable “Category” is imported as a numeric variable. The command levels() also shows that this is a variable that does not have values arranged according to a hierarchy. What follows is how to change the variable into a factor variable.
Text following “#” are comments and are not perceived by R as code, here I have translated the code into words.
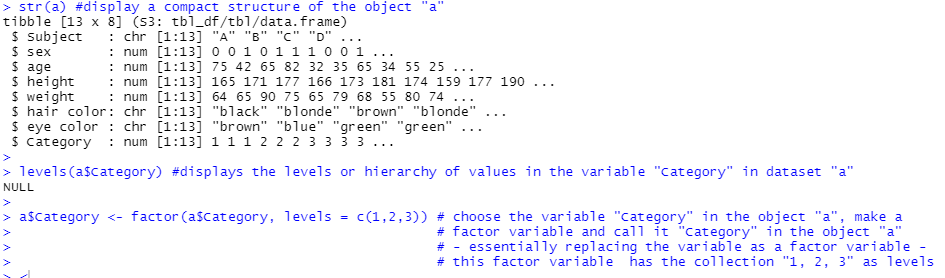
Values and subjects in the dataset are fictive.